
Kettle 输入组件
目录
表输入
组件说明
使用 SQL 通过数据源指定的数据库获取数据(从数据库中读取表数据)
组件预览
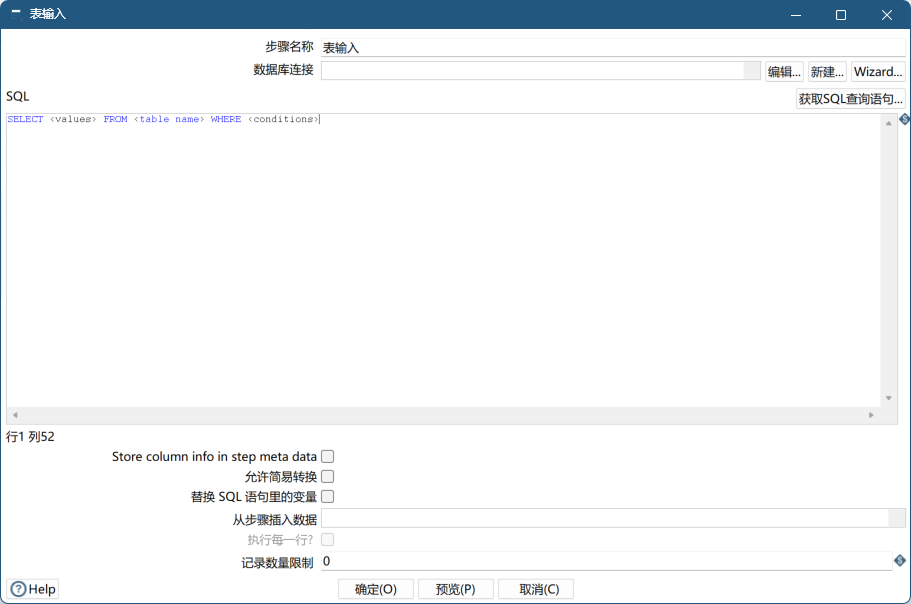
组件详解
- 数据库连接:数据源
- SQL:编写查询sql语句,也可以点击获取SQL查询语句按钮选择相应表生成sql语句
- Store column info in step meta data:以使用存储在KTR中的缓存元数据,而无需建立数据库连接来查询表
- 允许简易转换:启用简易转换算法。如果选择简易转换,则尽可能避免不必要的数据类型转换,这可以显著提高性能
- 替换SQL语句里的变量:使用变量时必须勾选,SQL 语句里面的变量如
${ID}会被替换 - 从步骤插入数据:选择流入步骤,然后SQL里面的占位符?会被替换。注意 前置步骤里面的输出字段数要和占位符的数量一致
- 执行每一行:和从步骤插入数据搭配使用,若前置步骤只有一条数据输出,则无需勾选,若前置步骤有多余一条数据输出,则需要勾选
- 记录数量限制:0表示不限制,可以填写大于0的数字,比如填写2作用和sql语句里面的
limit 2一样
注意:
- 可以使用变量替换的方式进行查询,请将“替换 sql 语句里的变量”勾选上
- 可以使用上一步结果中赋予值,请将“从步骤插入数据”选择上一步的名称
- 当 sybase 数据库同步含有中文字符的数据至其它库时,请将“允许简易转换” 勾选上
- 在预览时,会出现双精度的值显示不正常的问题,不影响实际输出值
- 测试过程中发现如果上一个步骤设置的变量,在 table input 里面获取不到,变量设置必须作为一个单独的转换先执行一次,然后才能获取到这个变量
组件示例
- 转换
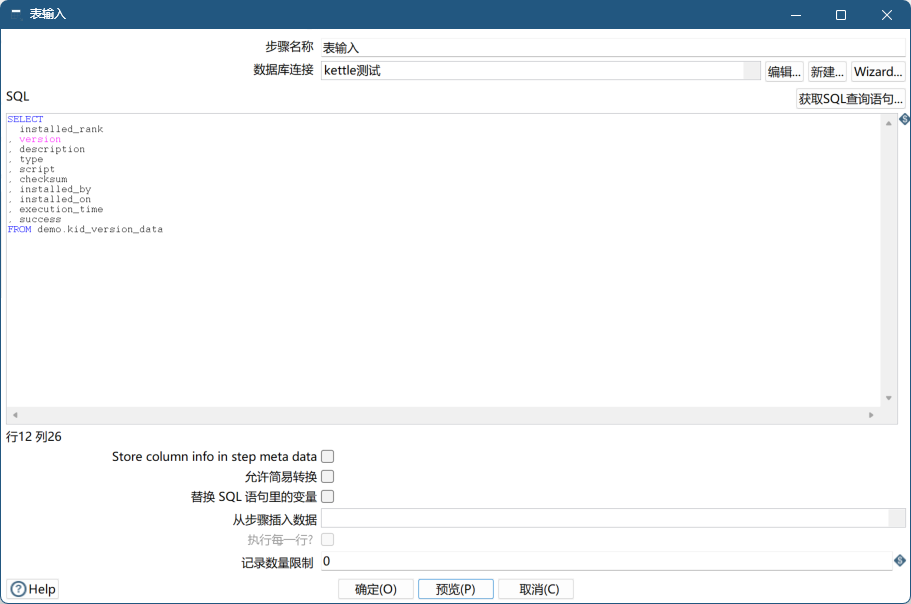
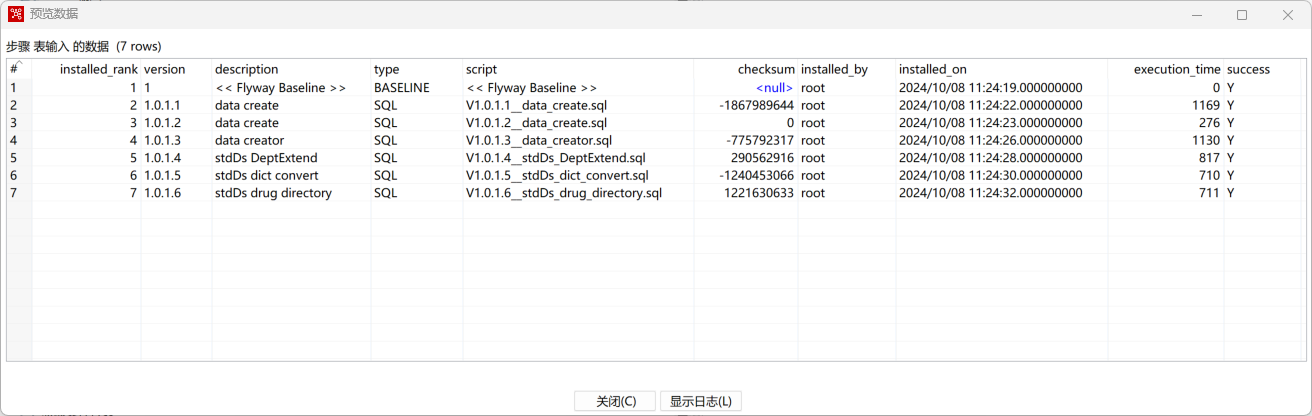
- 预览
CSV 文件输入
组件说明
读取 CSV 文件,CSV 文件是一个用逗号分隔且固定格式的文本文件。划重点:本质上就是文本文件
组件预览
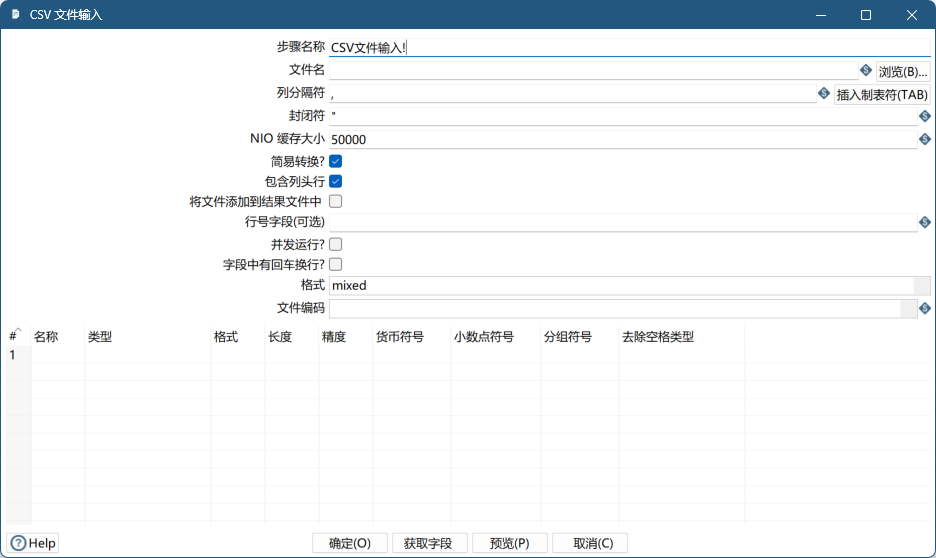
组件详解
- 文件名称:CSV 文件的相对路径或绝对路径。(包含文件名和扩展名,如:“d:/kettle/csv/test.csv”)
- 列分隔符:CSV 文件中字段分割的符号,即文件中每一列数据之间使用的分割符。(一般使用“,”,别问为啥,问就是国际惯例~~)
- 封闭符:CSV 指定源文件中使用的结束字符。(一般为空,kettle默认使用**"**作为分隔符)
- NIO的缓冲区大小:指定读取缓冲区的大小,指一次从源文件读取的字节数。
- 简易转换:设置是否可以使用延迟转换算法来提高性能。简易转换算法尽可能避免不必要的数据类型转换。它可以显著提高性能。
- 包含列头行:指示源文件是否包含列名的一个标题行。
- 将文件添加到结果文件中:将CSV源文件名添加到此转换的结果中。
- 行号字段(可选):指定将在此步骤的输出中包含数据的行号,即:行号
- 并行运行:设置是否将运行此步骤的多个实例(步骤副本),以及是否希望每个实例读取 CSV 文件的单独部分。当读取多个文件时,将考虑所有文件的总大小来分割工作负载。在这种特定的情况下,请确保所有步骤副本都接收到需要读取的所有文件,否则并行算法将不能正确工作。
- 字段中有回车换行?:设置数据字段是否可能包含换行字符。(CSV 每行数据通常使用回车符来分割,如果列字段中包含,需要通过该属性设置,避免解析出来的数据不准确)
- 格式:选择文件格式,可以是 DOS、UNIX 或 mixed 。UNIX 文件是以换行符结束的行。DOS 文件用回车符和换行符分隔的行。如果指定 mixed ,则不执行验证。
- 文件编码:指定源文件的编码,防止读取的数据乱码。(windows 下文件有时需要指定为 GBK 编码)
- 字段说明:(字段一般通过“获取字段”方式生成)
- 名称:字段的名称。
- 类型:字段的类型。
- 格式:用于转换原始字段格式的可选格式掩码。
- 长度:字段的长度取决于以下字段类型:Number:一个数字中有效数字的总数;String:字符串的总长度;Date:字符串打印输出的长度。
- 精度:用于数字类型字段的浮点数。
- 货币符号:用于表示货币的符号(例如$5,000或€5,000,00)。
- 小数点符号:小数点可以是"."或","(例如,5,000.00或5.000,00)。
- 分组符号:一个分组可以是","或"."(例如5,000.00或5.000,00)。
- 去除空格类型:应用于字符串的修剪方法。
组件示例
- 转换
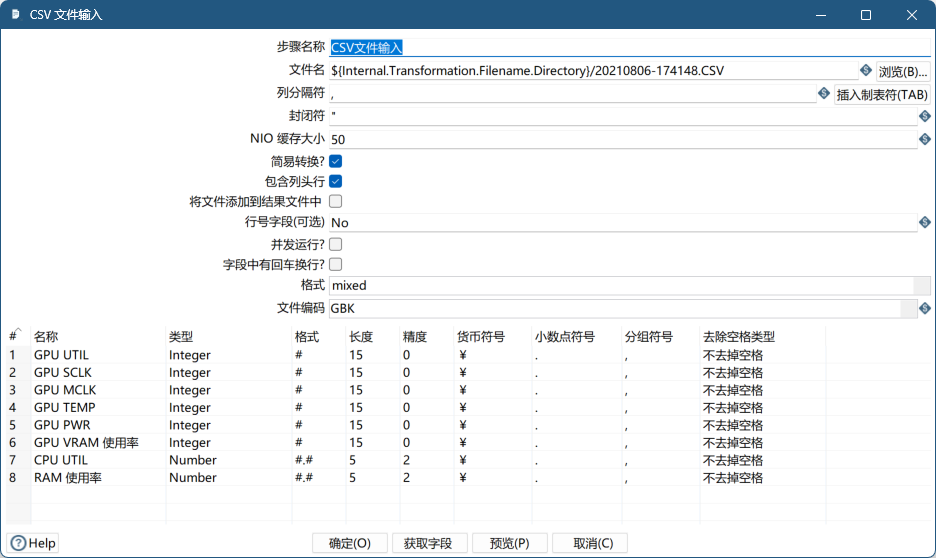
- 转换结果
组件扩展
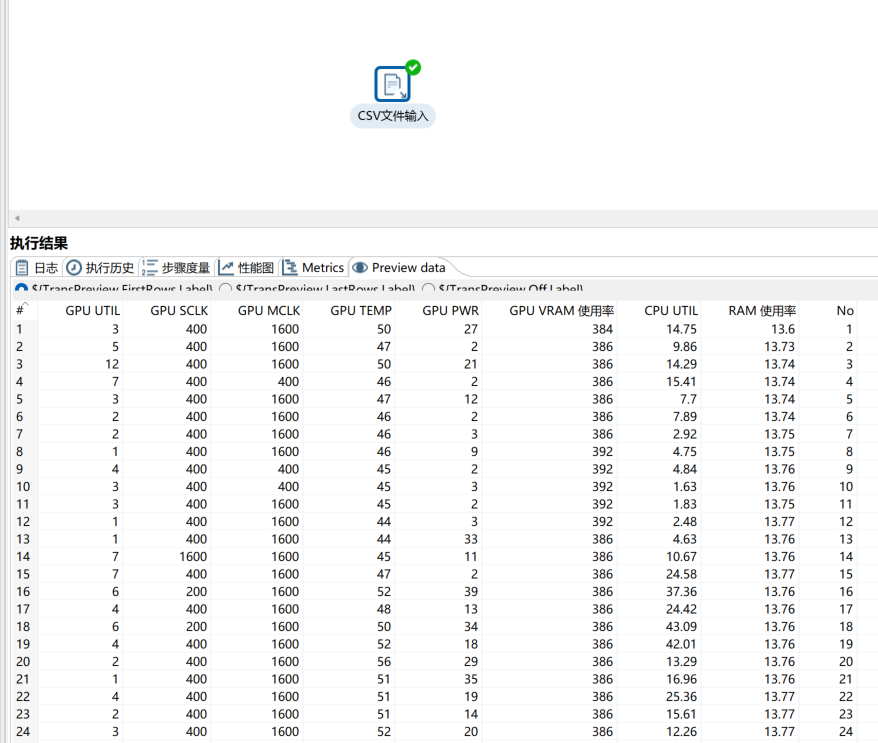
组件说明 中提到一个重点:CSV 文件本质上就是“文本文件”。那么 CSV 文件输入组件是否能读取 txt 文件呢
- 创建一个测试用txt
echo "id,name,age,sex\
> 1,Mars,36,男
> 2,luck,18,女" > test.txte
- 创建转换并执行
Excel 输入
组件说明
根据组件名就知道他是读取 excel 文件的~~~
组件预览
- !文件
- !工作表
- 内容
- 错误处理
- !字段
- 其他输出字段
组件详解
“文件”、“工作表”、“字段”选项卡的参数是必填项 (没有设置参数时,选项卡名称前面会显示“!”符号,表示是必填项,设置参数后“! ”符号会消失),并且必须按照“文件”,“工作表”,“字段”选项卡的顺序设置,其他为可选项
文件
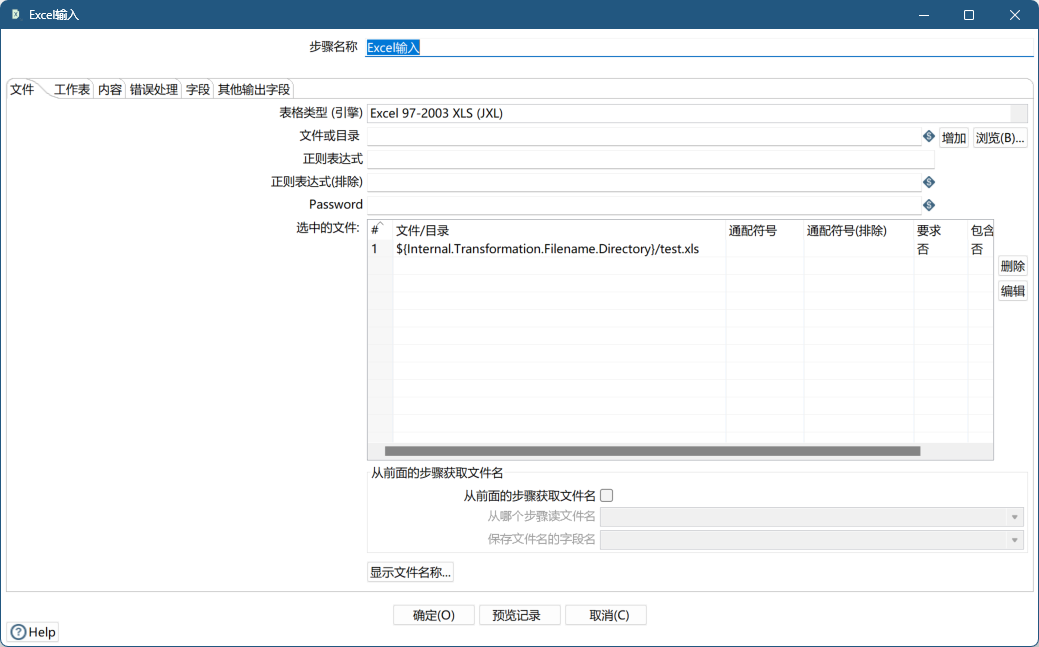
- 表格类型(引擎):excel 文件读取方式
| Excel 97-2003 XLS (JXL) | 扩展名为 xls | 使用 jxl 读取 |
| Excel 2007 XLSX (Apache POI) | 扩展名为 xlsx | 使用 poi 读取 |
| Excel 2007 XLSX (Apache POI Streaming) | 扩展名为 xlsx | 使用 poi streaming 方式读取,一般处理大型文件使用 |
| Open Office ODS (ODFDOM) | 扩展名为 xls | 使用 odfdom 读取 OpenOffice 电子表格 |
- 文件或目录:读取 excel 的全路径
- 正则表达式:根据正则表达式结果获取匹配的Excel文件
- 正则表达式(排除):与正则表达式相反,排除掉匹配的Excel文件
- password:读取 Excel 文件的密码
- 选中的文件:选中的 Excel 文件列表。通过单击 “增加” 按钮将文件或目录添加到列表中,并进行参数设置。
| 文件或目录 | 导入的文件或者要导入文件所在的目录(一般多文件时使用目录) |
| 通配符号 | 导入文件过滤。如导入同一个目录下名称分别为“物理成绩.xls”“物理成绩1.xls”和“物理成绩2.xls”的文件(“文件/目录”中配置路径(如:d:/tmp/,要求中配置为“物理成绩*.\xls”即可)) |
| 通配符号(排除) | 用法同“通配符号”,只不过用于排除 |
- 从前面的步骤获取文件名:是否从前面组件(步骤)读取文件名,如果选择是,则不用本组件获取Excel文件,而是从前面步骤的组件中读取文件、并保存文件的字段名。默认值为空。
工作表
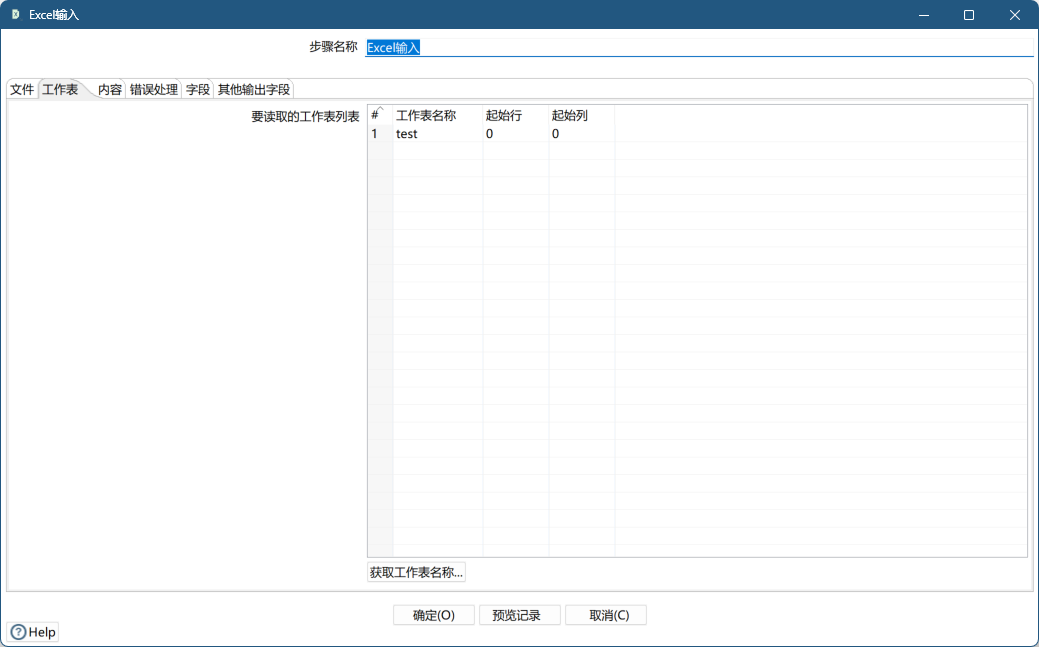
要读取的工作表列表:设置工作表参数,获取导入的 Excel 文件的工作表(即 sheet 页)
| 工作表名称 | 要读取的 excel sheet 页名称 |
| 起始行 | 从哪行开始读取,即读取的第一行 |
| 起始列 | 从哪列开始读取,即读取的第一列 |
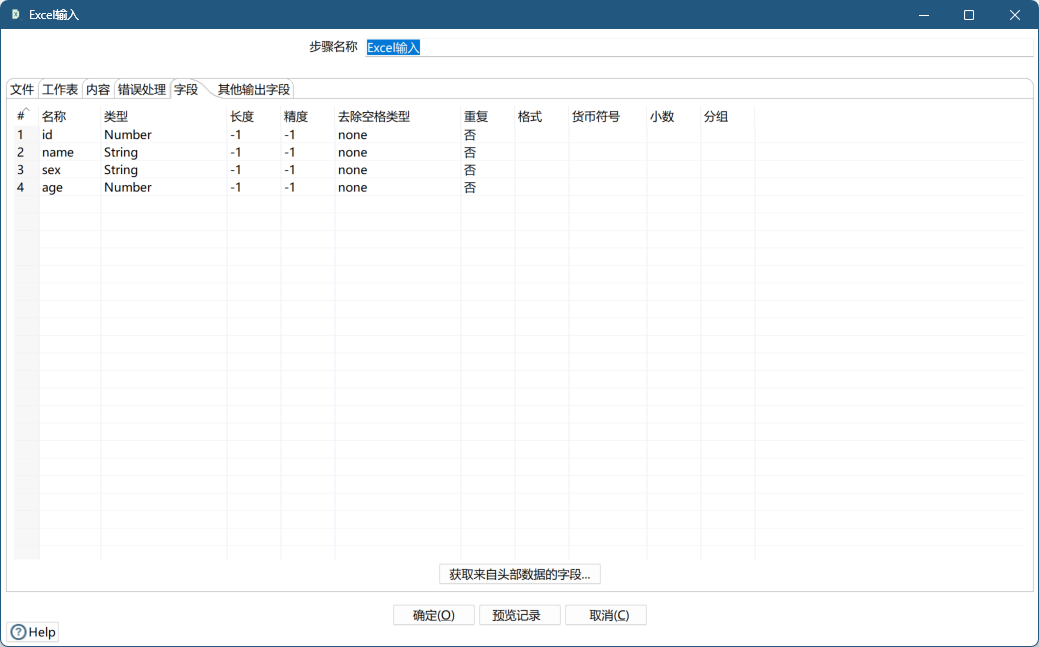
字段
设置 excel 文件中字段的参数及属性
内容
对读取Excel文件内容进行参数设置,一般按照缺省值配置。
- 头部:表示对选中的工作表是否包含表头行。默认值为√。
- 非空记录:表示是否在输出中不出现空行(记录)。默认值为√。
- 停在空记录:表示当读取记录遇到空行时,选择是否停止读取文件的当前工作表。默认值为空。
- 限制:表示限制生成的记录数量。当设置为0时,结果不受限制。默认值为0。
- 限制:表示读入的文本文件编码。第一次使用时,Kettle 会在系统中搜索可用的编码。使用 Unicode 的,请指定 UTF-8 或 UTF-16 。默认值为 Kettle 系统的编码。
错误处理
处理读取 Excel 文件时产生的错误处理参数进行设置,用于检查和定位错误位置,一般按照缺省值配置。
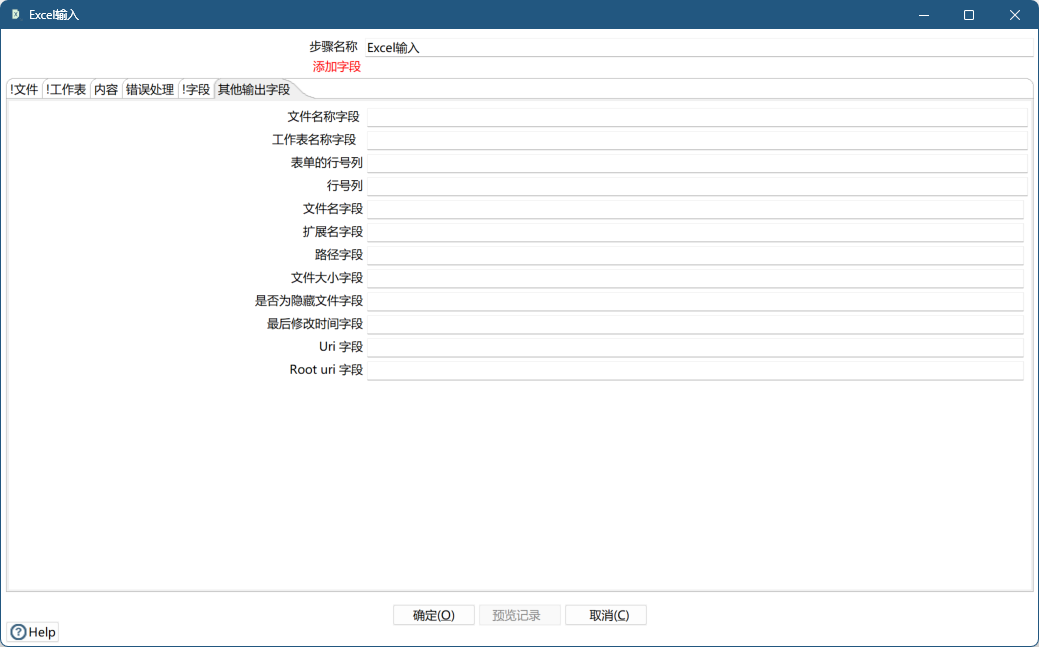
其他输出字段
对 Excel 文件的其他输出字段参数进行设置,用于指定处理文件的附加信息,默认值为空,一般按照缺省值配置。
| 文件名称字段 | 表示指定完整的文件名称和扩展名的字段。默认值为空 |
| 工作表名称字段 | 表示指定要使用的工作表名称的字段。默认值为空 |
| 表单的行号列 | 表示指定要使用的当前工作表行号字段。默认值为空 |
| 行号列 | 表示指定写入行数的字段。默认值为空 |
| 文件名字段 | 表示指定文件名但没有路径信息、但有扩展名的字段。默认值为空 |
| 扩展字段 | 表示指定文件名扩展名的字段。默认值为空 |
| 路径字段 | 表示指定以操作系统格式包含路径的字段。默认值为空 |
| 文件大小字段 | 表示指定文件数据大小的字段。默认值为空 |
| 是否为文件隐藏字段 | 表示文件是否为隐藏的字段(布尔值)。默认值为空 |
| Uri字段 | 表示指定包含Uri的字段。默认值为空 |
| Root Uri字段 | 表示指定仅包含uri的根部分的字段。默认值为空 |
组件示例
- 转换
- 文件设置
- 工作表设置
- 字段设置
- 预览记录
JSON input
组件说明
读取 json 结构的数据流或文件
组件预览
组件详解
文件
- 从字段获取源(通过数据流获取json)
- 源定义在一个字段里:json 报文是否在一个字段里
- 从字段获取源:如果字段在一个自读案例,选择哪个字段是 json 源
- 源是一个文件名:json 源是否是一个文件名
- 以 url 获取源:通过 url 获取 json
- Do not pass field downstream:选择将源字段从输出流中移除(不向下传递 json 数据字段),可以提高大型JSON字段的性能和内存利用率
- 通过文件获取json
- 文件或路径:文件或者文件的路径
- 正则表达式:获取文件的正则表达式(指定一个正则表达式来匹配指定目录中的文件)
- 正则表达式(排除):排除掉某些文件的正则表达式(指定一个正则表达式以排除指定目录中的文件名)
- 选中的文件:用法参考 Excel 输入 - 组件详解 - 文件
注意: 方式1和方式2不能同时使用。
内容
- 忽略空文件:选择跳过空文件。清除后,空文件将导致进程失败并停止
- 如果没有文件不要报告错误:当没有文件可供处理时,选择继续
- 忽略不完整的路径:当出现错误(1)没有字段匹配JSON路径或(2)所有值都为null时,选择继续处理文件。清除后,发生错误时不再处理其他行
- Default path leaf to null:如果选中,为缺少的路径返回一个null值
- Include null values:包含 null 值
- 限制:指定从该步骤生成的记录数量的限制。当设置为0时,结果不受限制
- 在输出中包含文件名:如果选中,则在结果中添加具有文件名的字符串字段
- 在输出中包含行数:选择此选项可在结果中添加带有行号的整数字段
- 添加文件名:选择将已处理文件添加到结果文件列表
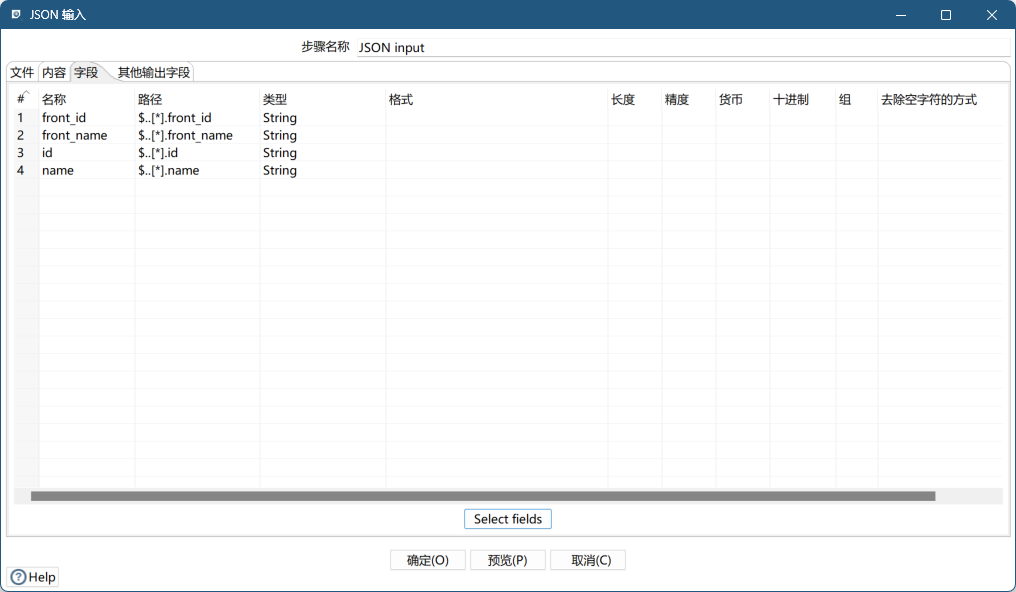
字段
- 参数说明
| 选项 | 描述 |
|---|---|
| 名称 | 映射到 JSON 输入流中相应字段的字段的名称。 |
| 路径 | JSON 输入流中字段名的完整路径。通过在路径中添加星号*,可以检索所有记录。 |
| 类型 | 输入字段的数据类型。 |
| 格式 | 用于转换原始字段格式的可选掩码。有关此步骤中可以使用的通用有效日期和数字格式的信息 |
| 长度 | 字段的长度。 |
| 精度 | 用于数字类型字段的浮点数。 |
| 货币 | 货币符号(例如$或€)。 |
| 十进制 | 小数点可以是.(例如,5,000.00)或(例如,5.000,00)。 |
| 组 | 分组可以是,(例如,10,000.00)或。(例如5.000,00)。 |
| 去除空字符串的方式 | 应用于字符串的修剪方法。 |
| 重复 | 如果行为空,则重复最后一行的对应值。 |
- select fields
只有在使用读取 json 文件时才生效。
Tips: 使用数据流时可以通过 JSON output 组件先输出一个文件,然后通过 JSON input 组件在读取文件,最后通过获取字段快速获取
- 路径(JsonPath)说明
以如下 json 结构为例
[
{
"front_id": "PRIMARY",
"front_name": "小学",
"id": "PRIMARY",
"name": "小学"
},
{
"front_id": "JUNIOR",
"front_name": "初中",
"id": "JUNIOR",
"name": "初中"
},
{
"front_id": "HIGH",
"front_name": "高中",
"id": "HIGH",
"name": "高中"
},
{
"front_id": "TECHNICAL",
"front_name": "中专/技校",
"id": "TECHNICAL",
"name": "中专/技校"
},
{
"front_id": "COLLEGE",
"front_name": "大专",
"id": "COLLEGE",
"name": "大专"
},
{
"front_id": "BACHELOR",
"front_name": "本科",
"id": "BACHELOR",
"name": "本科"
},
{
"front_id": "MASTER",
"front_name": "硕士",
"id": "MASTER",
"name": "硕士"
},
{
"front_id": "DOCTOR",
"front_name": "博士",
"id": "DOCTOR",
"name": "博士"
}
]
| JSONPath表达式 | 结果 |
|---|---|
| $.[*].name | 所有学历的name |
| $.[*].id | 所有的id |
| $.[*] | 所有元素 |
| $.[(@.length-2)].name | 倒数第二个元素的name |
| $.[2] | 第三个元素 |
| $.[(@.length-1)] | 最后一个元素 |
| $.[0,1]$.[:2] | 前面的两个元素 |
| $.[?(@.name =~ /.*大专/i)] | 过滤出所有的name包含“大专”的。 |
| $.[*].length() | 所有元素的个数 |
| $..front_id | 所有的front_id |
组件示例
- 转换
- test.json
[
{
"front_id": "PRIMARY",
"front_name": "小学",
"id": "PRIMARY",
"name": "小学"
},
{
"front_id": "JUNIOR",
"front_name": "初中",
"id": "JUNIOR",
"name": "初中"
},
{
"front_id": "HIGH",
"front_name": "高中",
"id": "HIGH",
"name": "高中"
},
{
"front_id": "TECHNICAL",
"front_name": "中专/技校",
"id": "TECHNICAL",
"name": "中专/技校"
},
{
"front_id": "COLLEGE",
"front_name": "大专",
"id": "COLLEGE",
"name": "大专"
},
{
"front_id": "BACHELOR",
"front_name": "本科",
"id": "BACHELOR",
"name": "本科"
},
{
"front_id": "MASTER",
"front_name": "硕士",
"id": "MASTER",
"name": "硕士"
},
{
"front_id": "DOCTOR",
"front_name": "博士",
"id": "DOCTOR",
"name": "博士"
}
]
- 预览
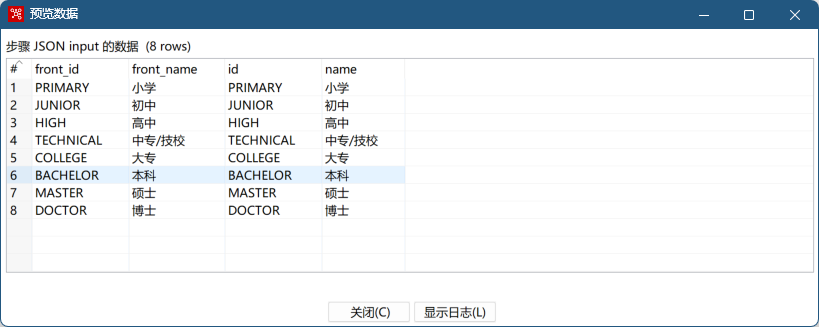
组件扩展(JSONPath)
操作符
| 操作 | 说明 |
|---|---|
| $ | 查询根元素。这将启动所有路径表达式。 |
| @ | 当前节点由过滤谓词处理。 |
| * | 通配符,必要时可用任何地方的名称或数字。 |
| . 或 [] | 子元素 |
| .. | 深层扫描。 必要时在任何地方可以使用名称。 |
.<name> | 点,表示子节点 |
['<name>' (, '<name>')] | 括号表示子项 |
[<number> (, <number>)] | 数组索引或索引 |
| [start:end] | 数组切片操作 |
[?(<expression>)] | 过滤表达式。 表达式必须求值为一个布尔值。 |
函数
可以在路径的尾部调用,函数的输出是路径表达式的输出,该函数的输出是由函数本身所决定的。
| 函数 | 描述 | 输出 |
|---|---|---|
| min() | 提供数字数组的最小值 | Double |
| max() | 提供数字数组的最大值 | Double |
| avg() | 提供数字数组的平均值 | Double |
| stddev() | 提供数字数组的标准偏差值 | Double |
| length() | 提供数组的长度 | Integer |
过滤器运算符
过滤器是用于筛选数组的逻辑表达式。
| 操作符 | 描述 |
|---|---|
| == | left等于right(注意1不等于'1') |
| != | 不等于 |
< | 小于 |
<= | 小于等于 |
> | 大于 |
>= | 大于等于 |
| =~ | 匹配正则表达式[?(@.name =~ /foo.*?/i)] |
| in | 左边存在于右边 [?(@.size in ['S', 'M'])] |
| nin | 左边不存在于右边 |
| size | (数组或字符串)长度 |
| empty | (数组或字符串)为空 |
Get data from XML
组件说明
读取 xml 结构的数据流或文件
组件预览
组件详解
文件
用法同 JSON input - 组件详解 - 文件
内容
| 选项 | 描述 |
|---|---|
| 循环读取路径 | 指的是 XML 文件中的层次结构,一般指定要读取的 XML 节点 |
| 编码 | 指的是 XML 文件的字符编码类型 |
| 考虑命名空间 | 选中此项即可识别 XML 文档名称空间 |
| 忽略注释 | 解析时忽略 XML 文档中的所有注释 |
| 验证XML | 在解析之前验证 XML |
| 忽略空文件 | 文件为空不读取数据 |
| 如果没有文件不要报告错误 | 如果没有找到文件,请不要报错。 |
| 限制 | 限制输出行数 |
| 用于截取数据的 XML 路径(大文件) | 和循环读取路径 基本一样,与处理大数据相关 |
| 输出中包括文件名 | 读入的每一行数据,都多了一个字段列,XML 的绝对路径 |
| 输出中包括行号 | 显示行数,为递增列 |
| 将文件增加到结果文件中 | 在一个转换中引用后,会把文件的名字保存到内存中,然后下一个 job 或者转换去引用 |
字段
| 选项 | 描述。 |
|---|---|
| 名称 | 设置要在输出流中显示的字段名称。 |
| XML路径 | 要读取的元素节点或属性的路径 |
| 节点 | 要读取的元素类型:节点或属性 |
| 结果类型 | 字段类型(String、Date、Number 等)。 |
| 格式 | 控制输入数据的格式(整数、有小数位、日期格式等) |
| 长度 | 对于Number:有效数的数量。对于String:字符的长度。对于Date:打印输出字符的长度(例如4 代表返回年份)。 |
| 精度 | 对于Number:浮点数的数量。对于String,Date,Boolean:未使用。 |
| 货币符号 | 用来解释如$10,000.00 的数字。 |
| 小数点符号 | 小数点可以是”.”(10;000.00)或者”,”(5.000,00)。 |
| 组 | 分组可以是”.”(10;000.00)或者”,”(5.000,00)。 |
| 去空字符串 | 处理之前先去空。 |
| 重复 | Y/N:如果在当前行中对应的值为空,则重复最后一次不为空的值。 |
其他输出字段
| 选项 | 描述 |
|---|---|
| 文件名字段 | 包括文件名称以及扩展名,以及文件路径的整体 |
| 扩展名字段 | 仅仅包括文件名称以及扩展名称 |
| 路径字段 | 仅仅包括文件的路径 |
| 文件大小字段 | 大小 |
| 是否为隐藏文件字段 | 是否隐藏 |
| 最后修改时间字段 | 最后一次此文件的修改时间 |
| Uri字段 | 文件/目录的绝对路径 |
| Root uri字段 | 根路径 |
组件示例
- 转换
- 文件
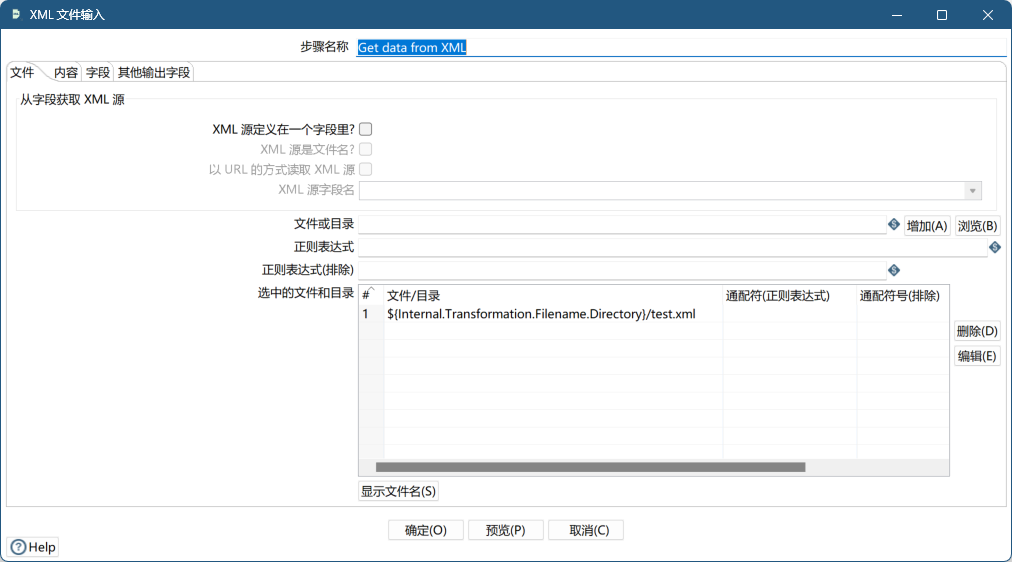
- 内容
- 字段
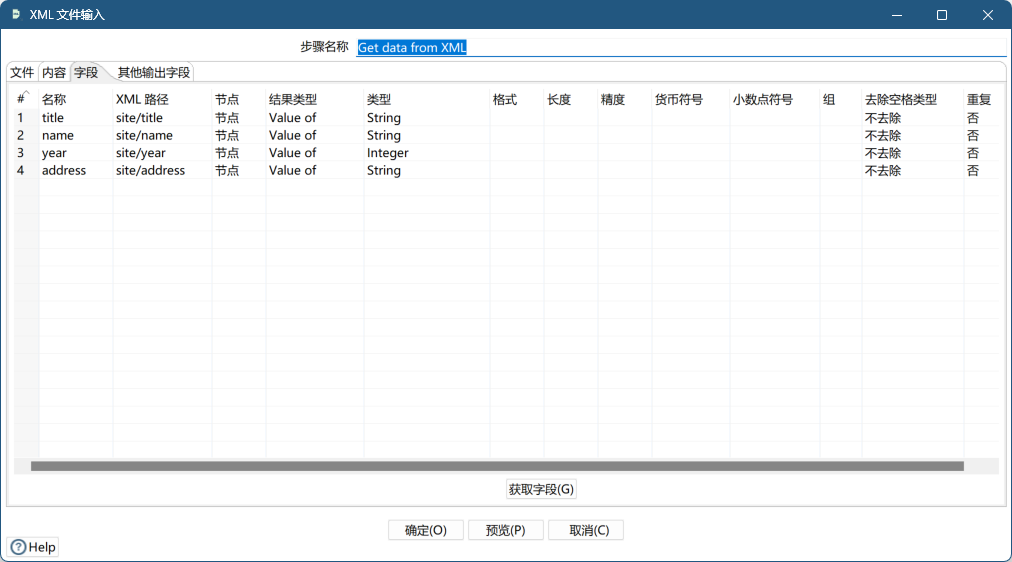
- test.xml
<?xml version="1.0" encoding="utf-8"?>
<website>
<site>
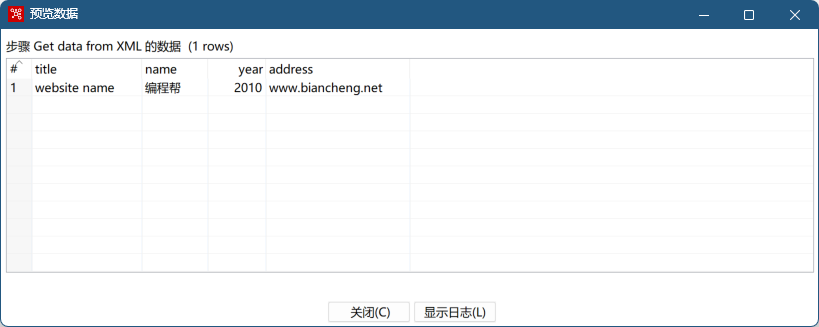
<title lang="zh-CN">website name</title>
<name>编程帮</name>
<year>2010</year>
<address>www.biancheng.net</address>
</site>
</website>
- 预览
组件扩展(Xpath)
操作符
| 表达式 | 描述 |
|---|---|
| node_name | 选取此节点的所有子节点。 |
| / | 绝对路径匹配,从根节点选取。 |
| // | 相对路径匹配,从所有节点中查找当前选择的节点,包括子节点和后代节点,其第一个 / 表示根节点。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性值,通过属性值选取数据。常用元素属性有 @id 、@name、@type、@class、@tittle、@href。: |
通配符
| 通配符 | 描述说明 |
|---|---|
| * | 匹配任意元素节点 |
| @* | 匹配任意属性节点 |
| node() | 匹配任意类型的节点 |
函数
| 函数名称 | xpath表达式示例 | 示例说明 |
|---|---|---|
| text() | ./text() | 文本匹配,表示值取当前节点中的文本内容。 |
| contains() | //div[contains(@id,'stu')] | 模糊匹配,表示选择 id 中包含“stu”的所有 div节点。 |
| last() | //*[@class='web'][last()] | 位置匹配,表示选择@class='web'的最后一个节点。 |
| position() | //*[@class='site'][position()<=2] | 位置匹配,表示选择@class='site'的前两个节点。 |
| start-with() | //input[start-with(@id,'st')] | 匹配 id 以 st 开头的元素。 |
| ends-with() | //input[ends-with(@id,'st')] | 匹配 id 以 st 结尾的元素。 |
| concat(string1,string2) | concat('C语言中文网',.//*[@class='stie']/@href) | C语言中文与标签类别属性为"stie"的 href 地址做拼接。 |
文本文件输入
组件说明
基本上和 CSV 输入一样,功能可以参考CSV 文件输入
组件详解
文件
参考CSV 文件输入 - 组件详解 - 文件
内容
| 选项 | 描述 |
|---|---|
| 文件类型 | 可以是 CSV 或者 Fixed length (固定长度)。 |
| 分隔符 | 在文本的单行中,一个或多个字符将被用来分隔字段,比较有代表性的是;或者一个tab 制表符。 |
| 文本限定符 | 一些字段能够被一对允许分隔的字符来封闭。封闭字符串是可选的。 |
| 逃逸字符 | 如果你的数据中有逃逸字符,就指定逃逸字符(或者逃逸字符串)。如果\作为逃逸字符,文本’Not the nineo\’clock news.’(’作为封闭字符),将被解析成Notthe nine o’clock news. |
| 头部/头部行数量 | 如果你的文本文件有头部行就使用这个。你可以指定头部行出现的次数。 |
| 尾部/尾部行数量 | 如果你的文本文件有尾部行就使用这个。你可以指定尾部行出现的次数。 |
| 包装行/包装行数量 | 利用这个来处理被某些页限制包装的数据行。注:头部和尾部从来不考虑被包装。 |
| 分页布局/每页行数/文档头部行 | 在行打印机上打印的时候,你可以用这个选项作为最终的手段。用头部行的数量来跳过介绍性的文本,用每页的行数来定位数据行。 |
| 压缩 | 如果你的文件是ZIP 文件或者GZIP 归档文件,就启用这个。注:此刻归档文件中仅仅第一个文件被读取。 |
| 没有空行 | 不往下一步发送空行。 |
| 文件名字段名称 | 包含文件名的字段名称。 |
| 输出包含行数 | 如果你想行数作为输出的一部分,可以启用这个。 |
| 行数字段名称 | 包含行数的字段名称。 |
| 根据文件获取行数 | 允许每个文件重置的行数。 |
| 格式 | 可以是DOS、UNIX 或者混合模式。UNIX 行终止可以是回车,DOS 中可以是回车或者换行。如果你选择混合模式,将不会验证。 |
| 编码方式 | 指定文本文件编码方式。如果不设置就使用系统默认的编码方式。如果想用Unicode,可以指定UTF-8 或者UTF-16。第一次使用的时候,Spoon 将搜索系统,寻找可用的编码。 |
| 记录数量限制 | 设置读取记录的行数。0 代表读取所有的。 |
| 解析日期时是否严格要求 | 如果你想严格的解析数据字段,可以禁用这个选项。如果启用的时候,Jan 32nd 将变成Feb 1st。 |
| 本地日期格式 | 在本地日期常常被解析为“February wnd,2006”的形式,在用法语本地化的系统中日期将不会被解析,因为在法语本地化中February 不能理解。 |
| 添加文件名 | 如果你想文件名作为输出的一部分,可以启用这个。 |
错误处理
当错误发生的时候,错误处理标签允许你指定这个步骤将重新做些什么
| 选项 | 描述 |
|---|---|
| 忽略错误 | 如果在解析的时候忽略错误,就指定这个选项。 |
| 忽略错误文件 | 使用这个选项来跳过那些出现错误的文件。 |
| 错误文件字段名 | 在输出流行中增加一个字段,这个字段将包含错误发生的文件字段名。 |
| 文件错误信息字段名 | 在输出流行中增加一个字段,这个字段将包含错误发生的文件信息 |
| 跳过错误行 | 使用这个选项来跳过那些出现错误的行。你可以生成另外的文件来包含发生错误的行号。如果不跳过错误行,解析错误字段将是空的。 |
| 错误计数字段 | 在输出流行中增加一个字段,这个字段将包含错误发生的行数。 |
| 错误字段文件名 | 在输出流行中增加一个字段,这个字段将包含错误发生的文件名。 |
| 错误文本字段名 | 在输出流行中增加一个字段,这个字段将包含解析错误发生字段的描述。 |
| 告警文件目录 | 当警告发生的时候,它们将被放进这个目录。文件名将是<警告目录>/文件名.<日期时间>.<警告文件扩展>。 |
| 错误文件目录 | 当错误发生的时候,它们将被放进这个目录。文件名将是<错误文件目录>/文件名.<日期时间>.<错误文件扩展>。 |
| 失败行数文件目录 | 当解析行的时候发生错误,行号将被放到这个目录。文件名将是<错误行目录>/文件名.<日期时间>.<错误行扩展>。 |
过滤
指定文本文件中要过滤的行
| 选项 | 描述 |
|---|---|
| 过滤字符 | 搜索字符串。 |
| 过滤位置 | 在行中过滤字符串必须存在的位置。0 是起始位置,如果你指定一个小于0 的值,过滤器将搜索整个字符。 |
| 停止在过滤器 | 如果你想在文本文件遇到过滤字符的时候,停止处理,就指定Y。 |
| 积极匹配 | 是: 将符合过滤器的数据保留, 否: 不保留符合过滤器的数据 |
字段
| 选项 | 描述。 |
|---|---|
| 名称 | 设置要在输出流中显示的字段名称。 |
| 类型 | 字段类型(String、Date、Number 等)。 |
| 格式 | 控制输入数据的格式(整数、有小数位、日期格式等) |
| 位置 | 不用管它 |
| 长度 | 对于Number:有效数的数量。对于String:字符的长度。对于Date:打印输出字符的长度(例如4 代表返回年份)。 |
| 精度 | 对于Number:浮点数的数量。对于String,Date,Boolean:未使用。 |
| 货币类型 | 用来解释如$10,000.00 的数字。 |
| 小数 | 小数点可以是”.”(10;000.00)或者”,”(5.000,00)。 |
| 分组 | 分组可以是”.”(10;000.00)或者”,”(5.000,00)。 |
| Null If | 空值如何处理。 |
| 默认 | 字段为空的时候的默认值。 |
| 去空字符串 | 处理之前先去空。 |
| 重复 | Y/N:如果在当前行中对应的值为空,则重复最后一次不为空的值。 |
其他输出字段
| 选项 | 描述 |
|---|---|
| 文件名字段 | 包括文件名称以及扩展名,以及文件路径的整体 |
| 扩展名字段 | 仅仅包括文件名称以及扩展名称 |
| 路径字段 | 仅仅包括文件的路径 |
| 文件大小字段 | 大小 |
| 是否为隐藏文件字段 | 是否隐藏 |
| 最后修改时间字段 | 最后一次此文件的修改时间 |
| Uri字段 | 文件/目录的绝对路径 |
| Root uri字段 | 根路径 |
生成记录
生成一些固定字段的记录,主要用来模拟一些数据进行测试
生成随机数
生成随机数,有七种方式:
- 随机数字:生成0到1之间的随机数
- 随机整数:生成一个32位的随机整数
- 随机字符串:基于64位长随机值生成随机字符串
- UUID:统一唯一标识符
- UUID4:统一唯一标识符类型4
- HmacMD5:HmacMD5随机消息认证码
- HmacSHA1:HmacSHA1随机消息认证
自定义常量数据
定义常量使用:
- 元数据:定义数据类型等
- 数据:设置数据常量
获取子目录名
获取指定路径的“子目录”名称
获取文件名
获取指定文件名,或获取指定目录下的文件名
获取文件行数
获取指定文件/目录文件行数
获取系统信息
获取命令行输入的参数,操作系统时间,ip 地址,一些特殊属性, kettle 版本等信息
获取表名
根据数据源获取数据库的表、视图、存储过程、同义词列表
配置文件输入
获取.properties配置文件内容
YAML 输入
获取.yaml文件内容